Rubric development for AI-enabled scoring of three-dimensional constructed-response assessment aligned to NGSS learning progression
Abstract
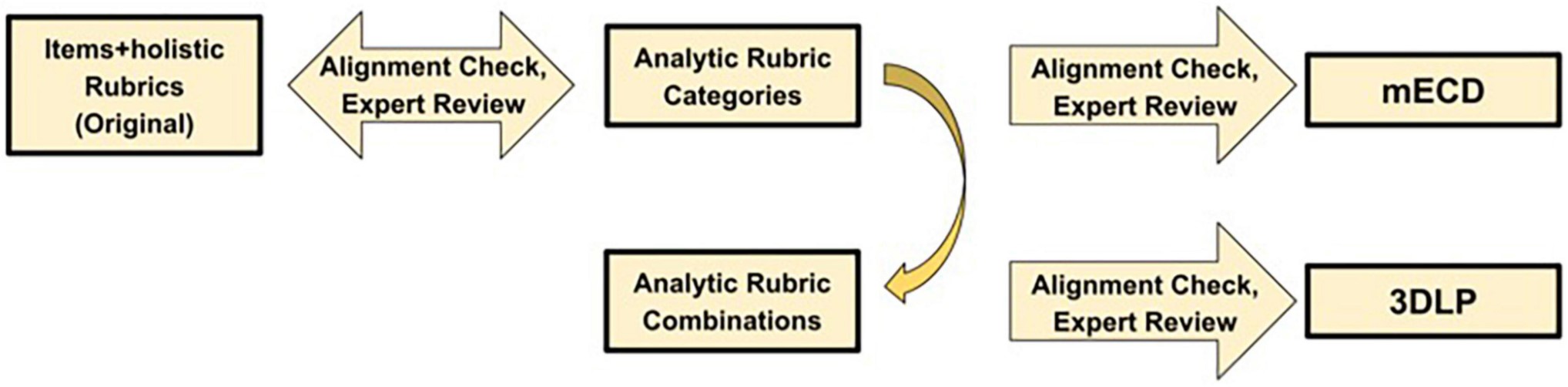
The Framework for K-12 Science Education (the Framework) and the Next- Generation Science Standards (NGSS) define three dimensions of science: disciplinary core ideas, scientific and engineering practices, and crosscutting concepts and emphasize the integration of the three dimensions (3D) to reflect deep science understanding. The Framework also emphasizes the importance of using learning progressions (LPs) as roadmaps to guide assessment development. These assessments capable of measuring the integration of NGSS dimensions should probe the ability to explain phenomena and solve problems. This calls for the development of constructed response (CR) or open-ended assessments despite being expensive to score. Artificial intelligence (AI) technology such as machine learning (ML)-based approaches have been utilized to score and provide feedback on open-ended NGSS assessments aligned to LPs. ML approaches can use classifications resulting from holistic and analytic coding schemes for scoring short CR assessments. Analytic rubrics have been shown to be easier to evaluate for the validity of ML-based scores with respect to LP levels. However, a possible drawback of using analytic rubrics for NGSS-aligned CR assessments is the potential for oversimplification of integrated ideas. Here we describe how to deconstruct a 3D holistic rubric for CR assessments probing the levels of an NGSS-aligned LP for high school physical sciences. We deconstruct this rubric into seven analytic categories to preserve the 3D nature of the rubric and its result scores and provide subsequent combinations of categories to LP levels. The resulting analytic rubric had excellent human- human inter-rater reliability across seven categories (Cohen’s kappa range 0.82–0.97). We found overall scores of responses using the combination of analytic rubric very closely agreed with scores assigned using a holistic rubric (99% agreement), suggesting the 3D natures of the rubric and scores were maintained. We found differing levels of agreement between ML models using analytic rubric scores and human-assigned scores. ML models for categories with a low number of positive cases displayed the lowest level of agreement. We discuss these differences in bin performance and discuss the implications and further applications for this rubric deconstruction approach.